// Find template <typename K, typename V> auto ExtendibleHashTable<K, V>::Bucket::Find(const K &key, V &value) -> bool { // Structured Binding make code looks pretty for (auto &[k, v] : list_) { if (k == key) { value = v; returntrue; } } returnfalse; }
// Remove template <typename K, typename V> auto ExtendibleHashTable<K, V>::Bucket::Remove(const K &key) -> bool { for (auto it = list_.begin(); it != list_.end(); it++) { if (it->first == key) { list_.erase(it); returntrue; } } returnfalse; }
// Insert template <typename K, typename V> auto ExtendibleHashTable<K, V>::Bucket::Insert(const K &key, const V &value) -> bool { // Check if a key already exists in the bucket. for (auto &[k, v] : list_) { if (k == key) { // Key already exists, update the value and return true. v = value; returntrue; } } // Key doesn't exist, add a new pair if the bucket isn't full. if (list_.size() < size_) { list_.emplace_back(key, value); returntrue; } // Bucket is full, return false. returnfalse; }
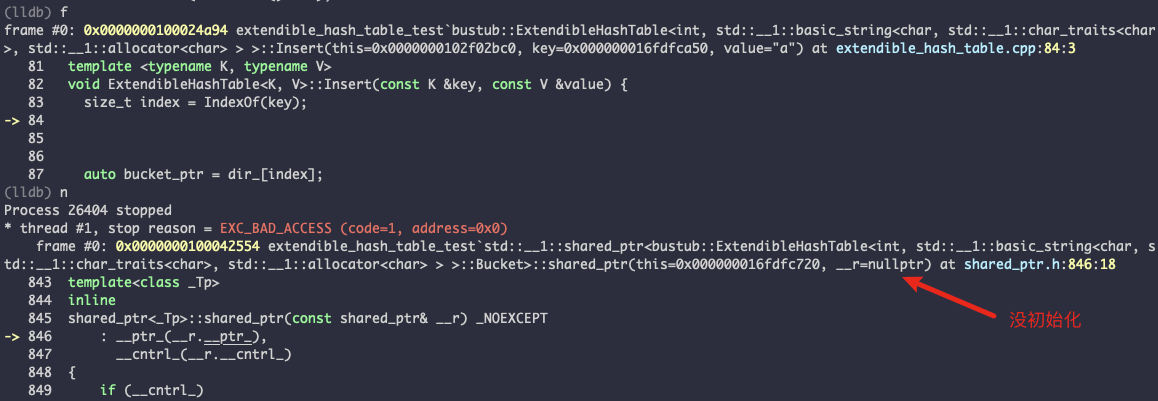
template <typename K, typename V> void ExtendibleHashTable<K, V>::Insert(const K &key, const V &value) { std::scoped_lock<std::mutex> lock(latch_);
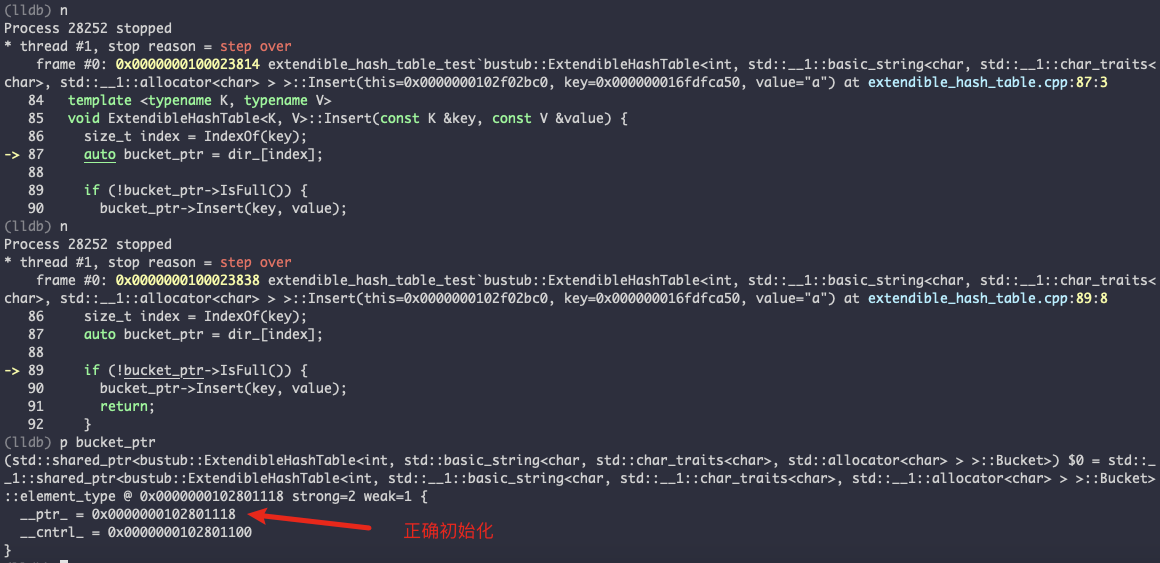
size_t index = IndexOf(key); auto bucket = dir_[index];
if (!bucket->IsFull()) { bucket->Insert(key, value); return; }
while (bucket->IsFull()) { // If the bucket is full, split it int local_depth = bucket->GetDepth(); if (local_depth == global_depth_) { size_t dir_size = dir_.size(); dir_.reserve(dir_size * 2); std::copy_n(dir_.begin(), dir_size, std::back_inserter(dir_)); global_depth_++; }
auto b0 = std::make_shared<Bucket>(bucket_size_, local_depth + 1); auto b1 = std::make_shared<Bucket>(bucket_size_, local_depth + 1); num_buckets_++;
int local_mask = 1 << local_depth;
// redistribute old bucket for (constauto &[k, v] : bucket->GetItems()) { auto new_index_of = std::hash<K>()(k) & local_mask; // new_index_of = {0, 1} if (new_index_of) { b1->Insert(k, v); } else { b0->Insert(k, v); } }
// update hashtable size_t start_index = std::hash<K>()(key) & (local_mask - 1); for (size_t i = start_index; i < dir_.size(); i += local_mask) { if (static_cast<bool>(i & local_mask)) { dir_[i] = b1; } else { dir_[i] = b0; } }
index = IndexOf(key); bucket = dir_[index]; } // now we have enough space to insert into dir_[index]->Insert(key, value); }
// FIFO, evict should start from head if (std::any_of(inactive_list_.begin(), inactive_list_.end(), [&](auto f) { bool evictable = table_[f].evictable_; if (evictable) { inactive_list_.remove(f); nr_evictable_--; table_.erase(f); *frame_id = f; } return evictable; })) { returntrue; }
// LRU, stores the most recently used items at the tail(my solution), // so evict should start from head if (std::any_of(active_list_.begin(), active_list_.end(), [&](auto f) { bool evictable = table_[f].evictable_; if (evictable) { active_list_.remove(f); nr_evictable_--; table_.erase(f); *frame_id = f; } return evictable; })) { returntrue; }
returnfalse; }
注意看,这里使用了 std::anyof 代替了 for 循环,这是 clang-tidy 要求的,Clang-Tidy: Replace loop by 'std::any_of()',原先我使用 for 循环写的,目的是可以用C++17 的结构体,另外我把 LRU 活跃缓存放在队尾也是为了能在这里使用结构化绑定,多简洁。 后来还是换成 std::anyof 了,因为不给换项目不给过。。
autoLRUKReplacer::Evict(frame_id_t *frame_id) -> bool{ for (auto f : inactive_list_) { bool evictable = table_[f].evictable_;
if (evictable) { inactive_list_.remove(f); nr_evictable_--; table_.erase(f);
*frame_id = f; returntrue; } }
for (auto f : active_list_) { bool evictable = table_[f].evictable_;
if (evictable) { active_list_.remove(f); nr_evictable_--; table_.erase(f);
// 构造函数 BufferPoolManagerInstance::BufferPoolManagerInstance(size_t pool_size, DiskManager *disk_manager, size_t replacer_k, LogManager *log_manager) : pool_size_(pool_size), disk_manager_(disk_manager), log_manager_(log_manager) { // we allocate a consecutive memory space for the buffer pool pages_ = new Page[pool_size_]; page_table_ = newExtendibleHashTable<page_id_t, frame_id_t>(bucket_size_); replacer_ = newLRUKReplacer(pool_size, replacer_k);
// Initially, every page is in the free list. for (size_t i = 0; i < pool_size_; ++i) { free_list_.emplace_back(static_cast<int>(i)); } }
新增一个 helper 函数
将寻找一个新的 frame 的操作抽象到一个函数 TryToFindAvailFrame 中。
// src/include/buffer/buffer_pool_manager_instance.cpp /** * @brief Try to find usable frame in buffer pool * @param[out] frame_id id of the page to deallocate * @return true if found, false if all frames are pined */ autoTryToFindAvailFrame(frame_id_t *frame_id) -> bool;