Lab1 为 xv6 实现用户态程序。
sleep 写第一个程序,主要的体会就是懵。不知道从哪下手,在看了内核态的对应实现,看了用户态 kill.c 的实现后,理清思路后,才发现 sleep 其实很简单。
#include "kernel/types.h" #include "user/user.h" int main (int argc, char **argv) { int ticks; if (argc != 2 ) { fprintf (2 , "usage: sleep ticks...\n" ); exit (1 ); } ticks = atoi(argv[1 ]); sleep(ticks); exit (0 ); }
pingpong 利用管道实现 pingpong,fork() 的父子进程都拥有同样的 fd,父子进程可以通过向一端写,另一端阻塞读来实现 ping-pong, 管道的规范是 pipe 的 0 是读,1 是写,记住这个很好实现了。
#include "kernel/types.h" #include "user/user.h" #define MAX_BUF_SIZE 32 int main (int argc, char ** argv) { int pipe_fds[2 ]; int nr_read = 0 ; int nr_write = 0 ; char buf[MAX_BUF_SIZE]; pipe(pipe_fds); if (fork() == 0 ) { nr_read = read(pipe_fds[0 ], buf, MAX_BUF_SIZE); if (nr_read > 0 ) printf ("%d: received ping\n" , getpid()); nr_write = write(pipe_fds[1 ], "ping-pong" , MAX_BUF_SIZE); if (nr_write < 0 ) exit (1 ); } else { nr_write = write(pipe_fds[1 ], "ping-pong" , MAX_BUF_SIZE); if (nr_write < 0 ) exit (1 ); nr_read = read(pipe_fds[0 ], buf, MAX_BUF_SIZE); if (nr_read > 0 ) printf ("%d: received pong\n" , getpid()); } exit (0 ); }
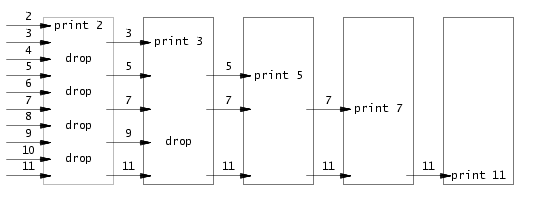
primes 利用 pipe + fork() 实现质数筛。核心思想如下图所示,首先一堆数 2-35,利用 2 将 2-35 树筛一遍,其中能被 2 整除的自然不是质数了,将不能被 2 整除的数保存下来,通过管道传递给子进程,子进程的得到的一系列数,利用第一个数 3 将不能被 3 整除的数保存下来,传递给子进程,接下来是 5,7 依次递归下去,每个进程打印出一个质数,最后结果就是所有质数。
#include "kernel/types.h" #include "user/user.h" #define MAX_NUMBER 35 void filter (int pipe_read) { int pipe_fds[2 ]; int primes[MAX_NUMBER]; int nr_read; int cnt = 0 ; while (1 ) { nr_read = read(pipe_read, & primes[cnt], sizeof (int )); if (nr_read <= 0 ) break ; cnt++; } close(pipe_read); if (cnt == 0 ) return ; int first = primes[0 ]; printf ("prime %d\n" , first); pipe(pipe_fds); for (int i = 1 ; i < cnt; i++) { if (primes[i] % first != 0 ) { write(pipe_fds[1 ], & primes[i], sizeof (int )); } } close(pipe_fds[1 ]); if (fork() == 0 ) { filter(pipe_fds[0 ]); } else { wait(0 ); } } int main (int argc, char * argv[]) { int pipe_fds[2 ]; pipe(pipe_fds); for (int i = 2 ; i < MAX_NUMBER; i++) { write(pipe_fds[1 ], & i, sizeof (i)); } close(pipe_fds[1 ]); filter(pipe_fds[0 ]); close(pipe_fds[0 ]); exit (0 ); }
find 为 xv6 实现一个简单的 find。核心是理解如何遍历目录下的所有文件(看代码中的注释),代码可以直接参考 xv6 的 ls.c 修改得来。
#include "kernel/types.h" #include "kernel/stat.h" #include "user/user.h" #include "kernel/fs.h" char *fmtname (char *path) { static char buf[DIRSIZ + 1 ]; char *p; for (p = path + strlen (path); p >= path && *p != '/' ; p--) ; p++; memmove(buf, p, strlen (p) + 1 ); return buf; } void find (char *dir, char *name) { char path[512 ]; char *p; int fd; struct dirent de ; struct stat st ; if ((fd = open(dir, 0 )) < 0 ) { fprintf (2 , "find: cannot open %s\n" , dir); return ; } if (fstat(fd, &st) < 0 ) { fprintf (2 , "find: cannot stat %s\n" , dir); close(fd); return ; } switch (st.type) { case T_FILE: if (strcmp (fmtname(dir), name) == 0 ) printf ("%s\n" , dir); break ; case T_DIR: if (strlen (dir) + 1 + DIRSIZ + 1 > sizeof path) { printf ("find: path too long\n" ); break ; } strcpy (path, dir); p = path + strlen (path); *p++ = '/' ; while (read(fd, &de, sizeof (de)) == sizeof (de)) { if (de.inum == 0 ) { continue ; } memmove(p, de.name, DIRSIZ); p[strlen (de.name)] = 0 ; if (strcmp (de.name, "." ) == 0 || strcmp (de.name, ".." ) == 0 ) continue ; find(path, name); } break ; } close(fd); } int main (int argc, char *argv[]) { if (argc != 3 ) { printf ("Usage: find [path] [name]" ); exit (0 ); } find(argv[1 ], argv[2 ]); exit (0 ); }
xargs 为 xv6 实现一个 xargs。理解 xargs 的工作原理对于实现 xargs 是至关重要的。
$ echo hello too | xargs echo bye bye hello too
xargs 是从标准输入(stdin) 读取输入,并将输入作为自己的输入。所以上面的 echo 示例程序,首先 shell 执行 echo hello too 产生的 stdout 通过管道作为 xargs 的 stdin。然后 hello too 会被追加到 bye 后面,所以最终命令的结果是 bye hello too。
#include "kernel/types.h" #include "kernel/stat.h" #include "kernel/param.h" #include "user/user.h" #define BUF_SIZE 512 char *args[MAXARG];int main (int argc, char *argv[]) { if (argc > MAXARG) { printf ("xargs: too many args\n" ); exit (1 ); } int index = 0 ; for (int i = 1 ; i < argc; i++) { args[index] = argv[i]; index++; } char buf[BUF_SIZE]; char *p = buf; while (read(0 , p, 1 ) == 1 ) { if (*p == '\n' ) { *p = 0 ; if (fork() == 0 ) { args[index] = buf; exec(argv[1 ], args); } else { wait(0 ); memset (buf, 0 , sizeof (buf)); p = buf; } } else { p++; } } exit (0 ); }
测试结果 最后 make grade 查看结果,
== Test sleep, no arguments == $ make qemu-gdb sleep, no arguments: OK (3.5s) == Test sleep, returns == $ make qemu-gdb sleep, returns: OK (0.9s) == Test sleep, makes syscall == $ make qemu-gdb sleep, makes syscall: OK (1.1s) == Test pingpong == $ make qemu-gdb pingpong: OK (1.0s) == Test primes == $ make qemu-gdb primes: OK (1.0s) == Test find, in current directory == $ make qemu-gdb find, in current directory: OK (1.1s) == Test find, recursive == $ make qemu-gdb find, recursive: OK (1.3s) == Test xargs == $ make qemu-gdb xargs: OK (1.5s) == Test time == time: OK Score: 100/100
至此, lab 的所有程序都结束了。下面的部分对于我们舒服的写代码有很大帮助,介绍了如何为 vscode 配置 clangd + clang-format 提供 xv6 的代码自动跳转以及格式化。